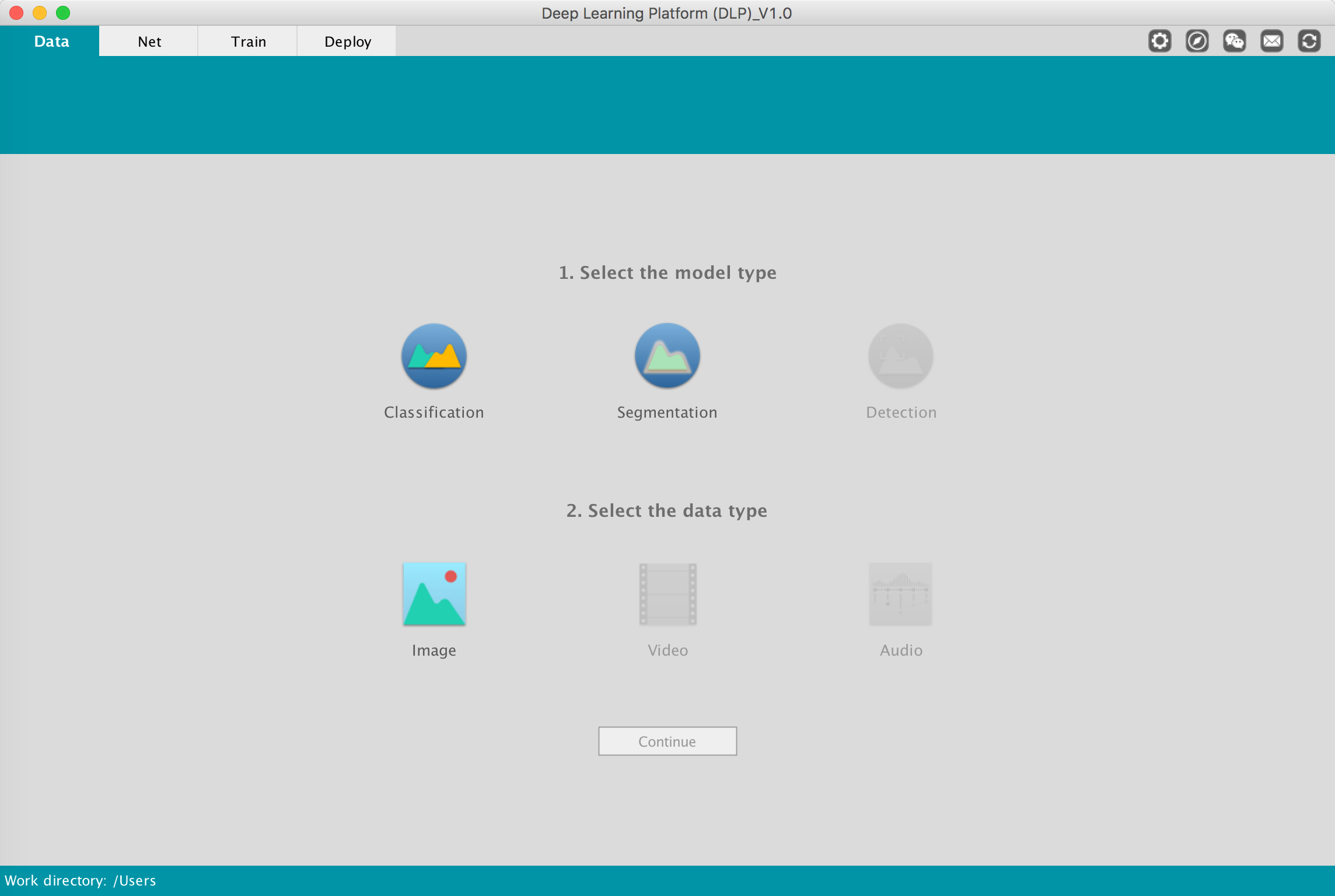
All the above, except for the Get The Data part, will be done within DLP. Before we get started, let's launch DLP. Once launched, you are greeted with the screen below.
Here we have many combinations of options to choose from. Under the "1. Select the model type" select Classification, and under "2. Select the data type" select Image, then click on Continue and you will land on the following page.
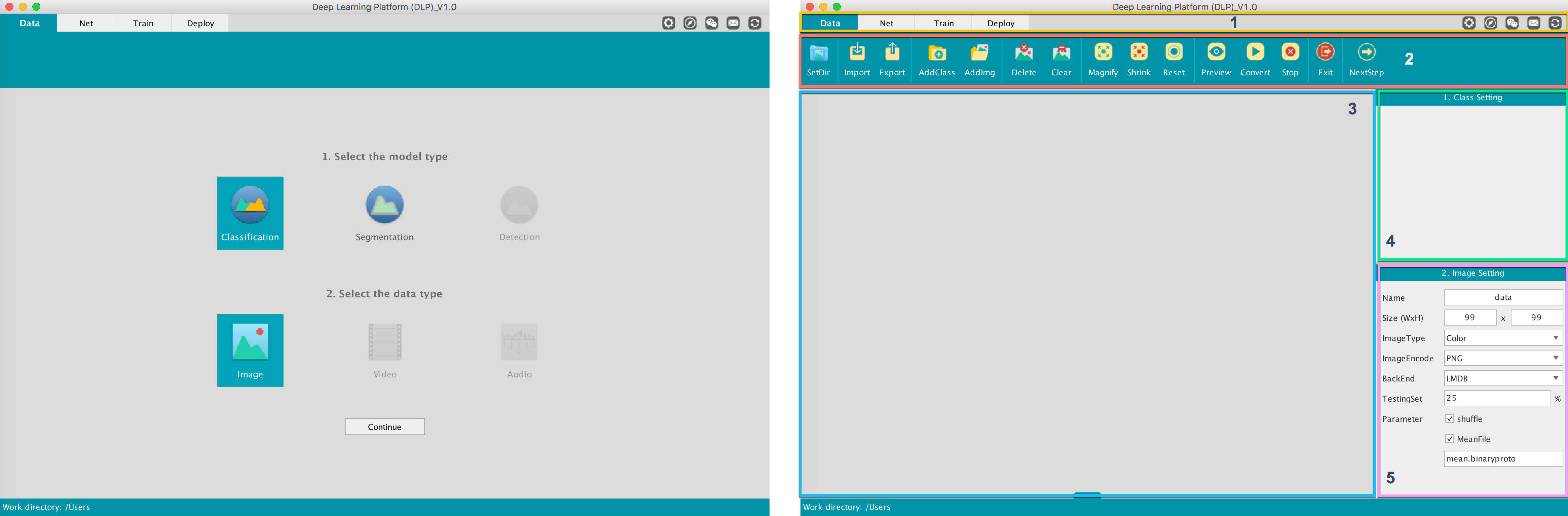
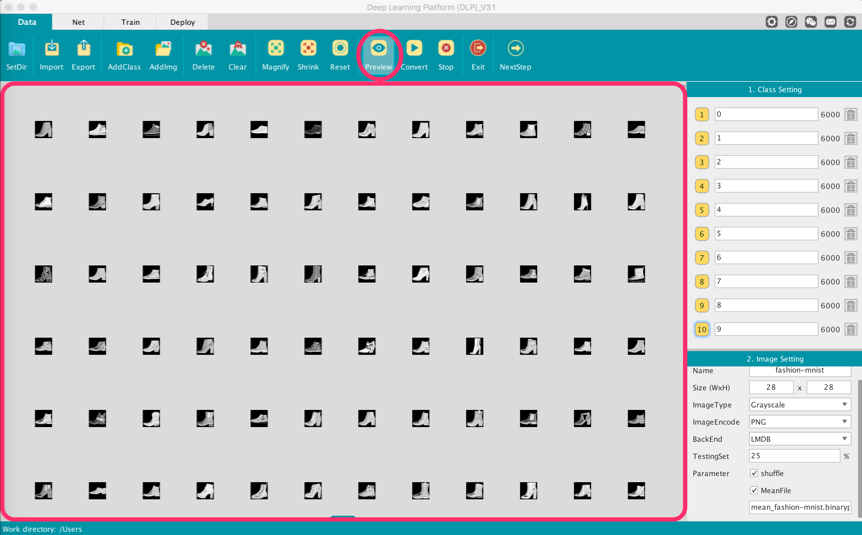
This interface is where all of our data preprocessing work for classification will take place. But before we get into it, first let's familiarize ourselves with this interface's main parts:
Navigation Bar: Contains controls to switch between different modules inside DLP, a dropdown button (where you will have to set paths for your caffe/build/tools, caffe/python, and python bin directory), and buttons linking to our social media pages.
Function Bar: Contains controls to stop/exit your project, and ways to set your working directory and add images/classes among other things.
Visualization Area: The main area where you will manipulate your images.
Class Setting: Contains the number of classes defined for your classification task along with the number of images in each class.
Image Setting: Contains configurable settings for your image data.
Well now that we are somehow acquainted to our interface, let's jump headfirst and start interacting with it.
Dataset Description
In this tutorial, we will be using the fashion-mnist dataset. This dataset was introduced by researchers at Zalando, an e-commerce company, as a drop-in replacement for the popular MNIST dataset. Fashion-mnist contains images of various articles and clothing items - such as shirts, shoes, bags, coats and other fashion items - consisting of a training set of 60,000 examples and a test set of 10,000 examples. Similar to MNIST, each example is a 28x28 grayscale image associated with a label from 10 classes (t-shirts, trousers, pullovers, dresses, coats, sandals, shirts, sneakers, bags, and ankle boots). Below is an example how the data looks, where each class takes three-rows.
Let's train a Caffe model to classify these images using DLP.
Get The Data
But first, we need to download the image dataset from here: fashion_mnist_data.tar.gz. The fashion_mnist_data.tar.gz file has the following directory structure:
<training/testing> / <label> / <id>.png
The training folder contains labeled png images that will be used to train our Caffe model. The testing folder contains labeled png images as well, but these images will be used to evaluate our trained Caffe model.
Dataset Preparation
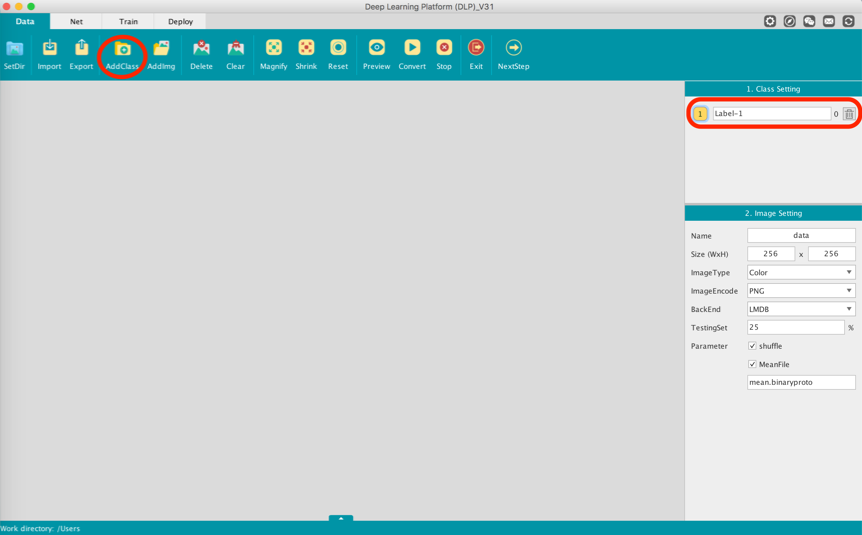
DLP can be used to help visualizing and organizing your dataset in a very easy and intuitive way. Head back to DLP from where we left it and under the Function Bar click on AddClass, and an editable label area under the Class Setting panel will show up:
From there you can give your label/class a name. Since Fashion-mnist is a 10-class dataset, we are going to repeat the above procedure 9 more times and labeled our class from 0-9:
If you pay attention to the highlighted area in the above screenshot, you will notice that there is a number between each label area and its corresponding trash icon. This number (currently 0 for all labels) indicates the number of images in each class. And since all we have done so far was just adding class label, each class label has zero image for now. For each class label, let's add the associated images.
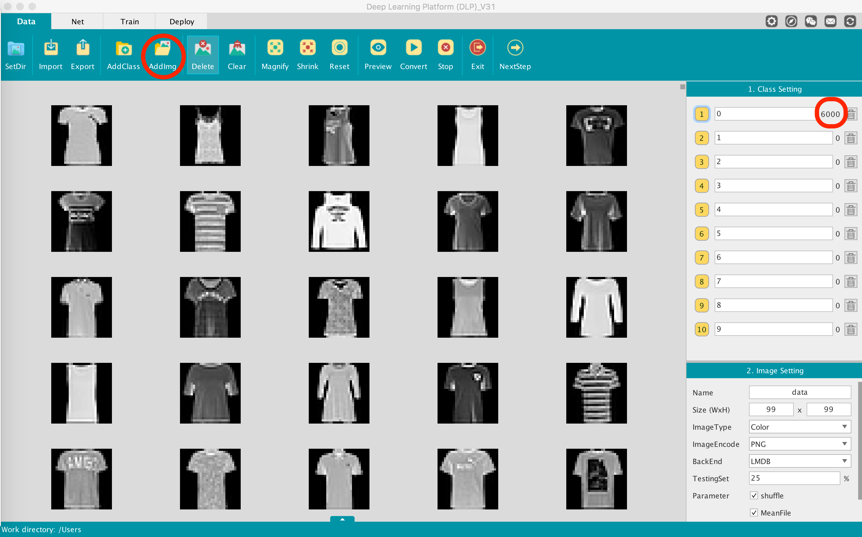
In order to add images corresponding to a specific class label, first click on the yellow box in front of the label area then under the Function Bar click on AddImg, and navigate to the folder in your machine containing the images corresponding to the specific label you have selected under the Class Setting. For instance, to add images corresponding to label 0 (T-shirt/top actually), within your fashion_mnist_data folder navigate to: /training/0.
You notice that the number indicating the number of images for the class label 0 has changed from 0 to 6,000. This means our dataset contains 6,000 images for this label. We do the same for the remaining classes. This is an easy and clean way to visualize and inspect your dataset; whether you want to add more images for a given class label or simply delete some images in a given class.
Now that our images are imported into DLP, we need to store them in a format that can be used to train a Caffe model.
Under the Image Setting panel - located right under the Class Setting panel- you can give a name to your dataset, set the Size option to 28x28 and the ImageType to Grayscale (since we are dealing with 28x28 grayscale images). Select PNG for the ImageEncode, and LMDB for the BackEnd. Set the TestingSet to a percentage of your choice (for instance 25) and select shuffle and MeanFile for the Parameters. You then have to give a name to the meanfile that will be generated.
Basically, these settings mean that we are dealing with 28x28 grayscale images encoded into the png format. The data will first be shuffled then stored as lmdb, and 25% of the training set will be used as validation set. While creating the lmdb files for our training and validation data, we will also generate the mean image of the training data.
Once you have defined your Image Setting, you can preview your changes by clicking on the Preview command on the Function Bar. And you will notice that in the Visualization Area your images size have changed to match the size defined in the Image Setting panel.
Now make sure that your /caffe/build/tools/ and /caffe/python/ paths are set properly.
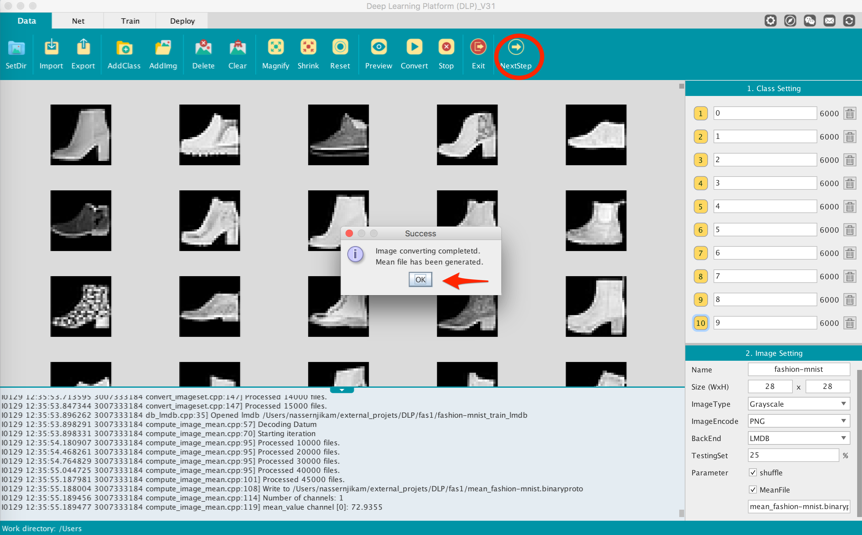
Then proceed with the data transformation -as defined under the Image Setting panel- by heading to the Function Bar and clicking on the Convert command. You will then be asked to select a location where you will like the files - that will be generated - to be saved… and that's it. Typically the Convert command will split your initial dataset into training and validation sets. Then for each data set, it will store the images as lmdb files ready to be fed to a Caffe model. The mean image of the dataset will also be generated.
If everything goes well, a "Success" window will pop up. Click ok, and then move to the network definition module by clicking on the NextStep command located on the Function Bar.
Model Definition
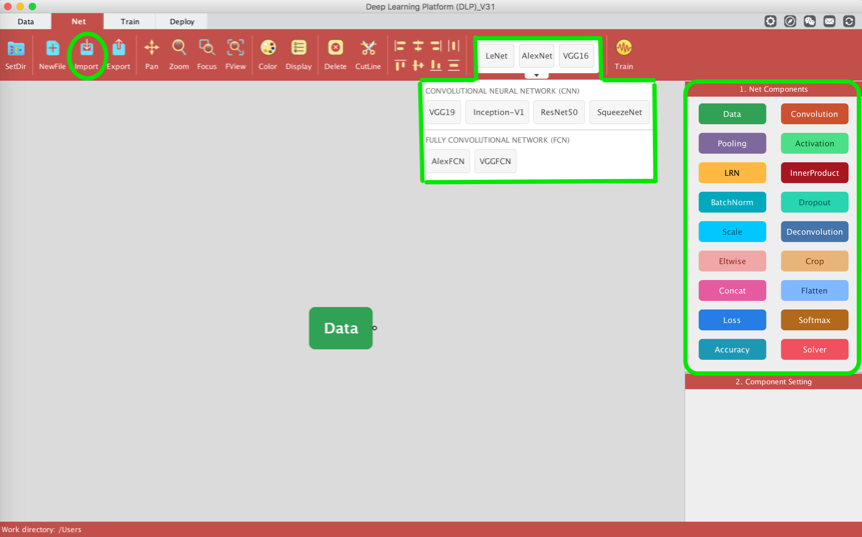
This is where you define your model architecture and its parameters. Here you can import your .prototxt train_val file into DLP, build up a net architecture from an existing architecture or from scratch using DLP Net Components in a simple drag and drop fashion, or you can simply use one of the predefined net architectures in DLP net library.
In this tutorial we will go for the latter, i.e. we will use one of the net defined in DLP net library. More specifically, we are going to use the popular LeNet architecture.
Simply left-click into the LeNet command in the net library then drag it into the Visualization Area and drop:
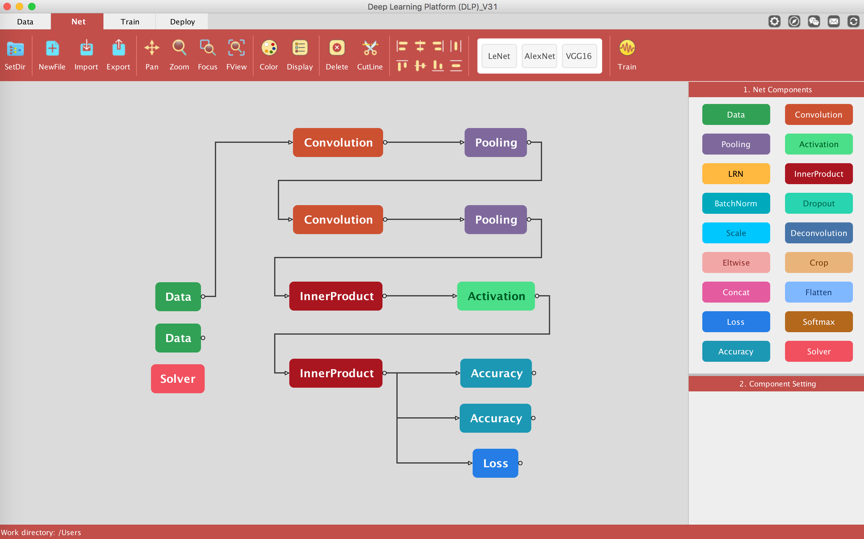
In the Visualization Area you will get a visualization of the LeNet architecture. Each component/layer of the net are clickable, and clicking on a specific component will allow you to define/inspect its parameters under the Component Setting panel.
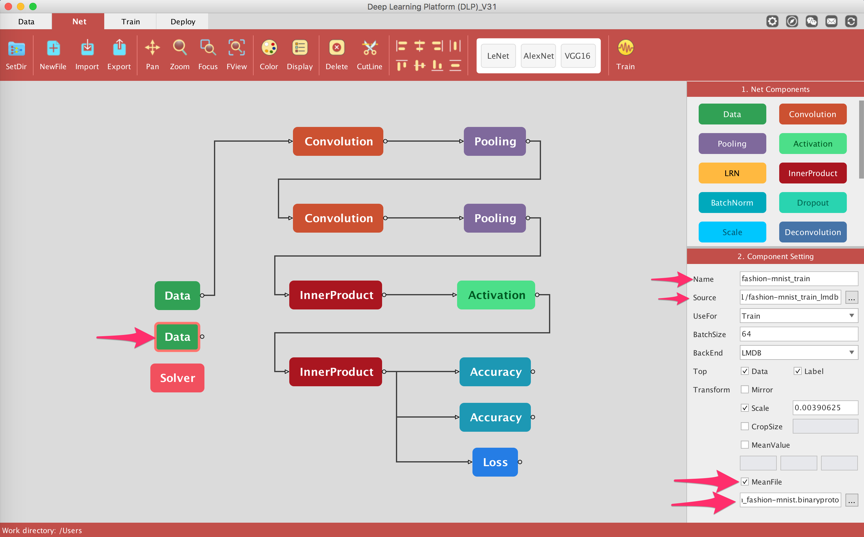
We are going to modify some of the default settings for some of the LeNet components. Let's start with the Data layers. Typically we want to modify the name associated to each data layer, paths to the lmdb files corresponding to the training and validation set, and include the mean file of the training data.
We do the same for the Data layer corresponding to the validation set (the one connected to the Convolution layer).
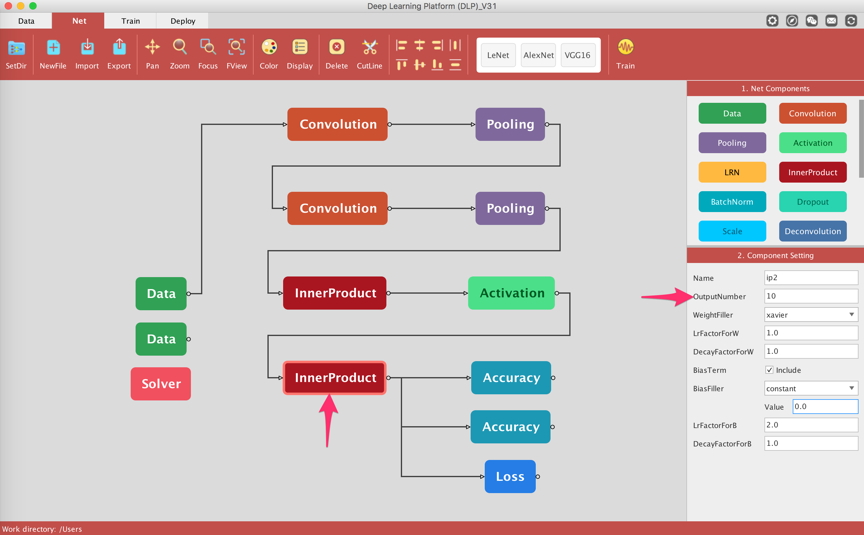
Next we have to make sure that the output number from the last InnerProduct layer actually matches the number of classes of our classification problem, which are 10.
You may have noticed this LeNet architecture contains two accuracy layers: one is to compute the accuracy for the LeNet by comparing the true label to the top k scoring classes, and the other does the same thing but instead of comparing the true label to the top k scoring classes it only compares it to the top scoring class. By default k = 3, you can change the default value if you like to.
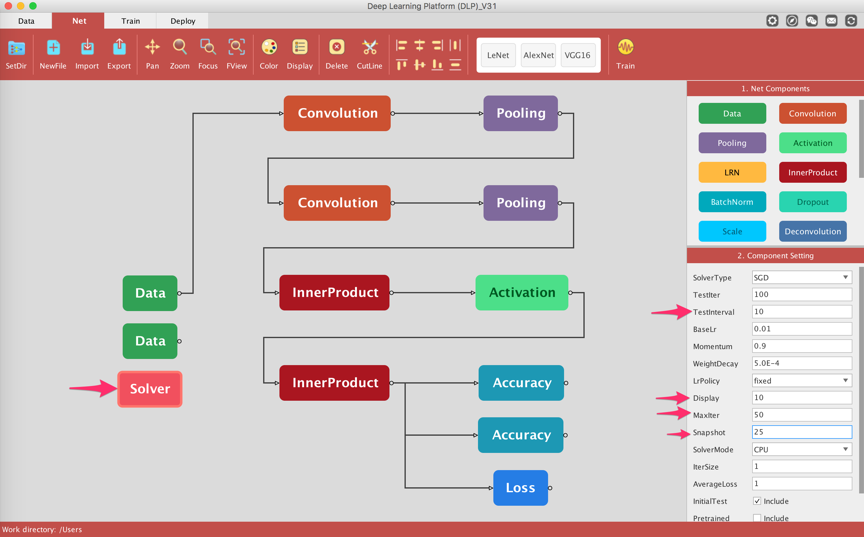
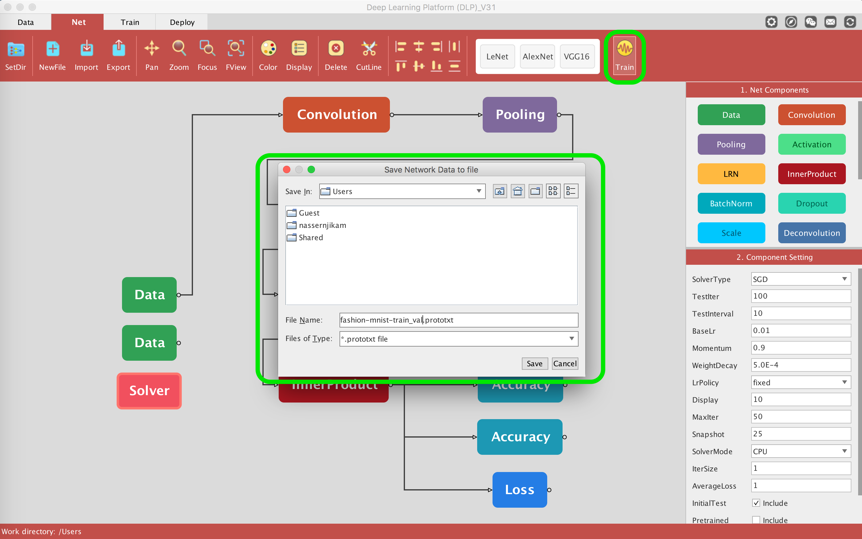
Now that our net is ready, it's time to define its solver component. The solver is responsible for model optimization. Select the solver component and inspect and/or modify its parameters under the Component Setting panel. You can leave it to default values, or change the value of some properties.
I have opted to train the model for 50 iterations, save a snapshot every 25 iterations, display the training log every 10 iterations, and validate the training on the validation set every 10 iterations as well. You can define the "SolverMode" to GPU if you have installed DLP on a machine with a GPU.
Now that we have made the appropriate changes into LeNet architecture to fit our classification problem and have defined the solver accordingly, it is now time to train our model. Click on the Train command and you will be asked to select a destination folder (that will host the generated .prototxt files and caffemodels).
Model Training
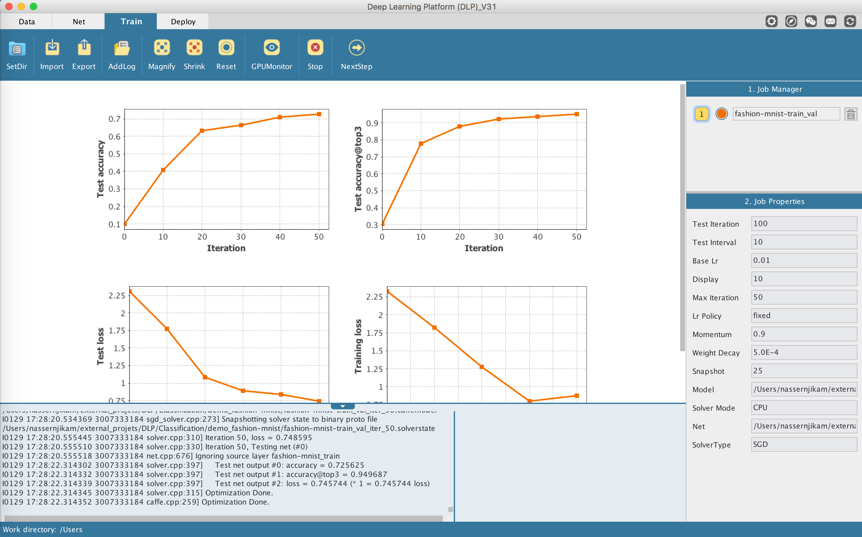
The Train command will direct you to DLP train module and will automatically kick start the training.
Here we can monitor the training either by visualizing plots for the training/test loss, as well as plots for the model accuracies (top 1 and top 3) on the validation set, or by inspecting the log panel beneath the Visualization Area. The training logs, .prototxt files, and caffemodels will be stored inside the folder you selected when you clicked on the Train command.
After 50 epochs, the top-1 accuracy on the validation set is around 72%, while the top-3 accuracy clocked at around 94%. A steady decrease in the training/validation loss can also be observed.
Now that we have trained a Caffe model, we can use it to make predictions on new unseen data (images from the test set, for instance).
Prediction On New Data
Click on the NextStep command to head to the Deploy module.
The Deploy module interface is rather intuitive. To start making predictions on new images data, there are a number of files we first need to prepare: a deploy.prototxt file, and a text label file. Create a .txt file with your favorite code editor, and for each line write down the name of each of the (fashion-mnist) 10-classes in this order:
The deploy_fashion-mnist.prototxt file can be downloaded from here. Its structure is similar to the fashion-mnist-train_val.prototxt (generated in step4) but with a few modifications.
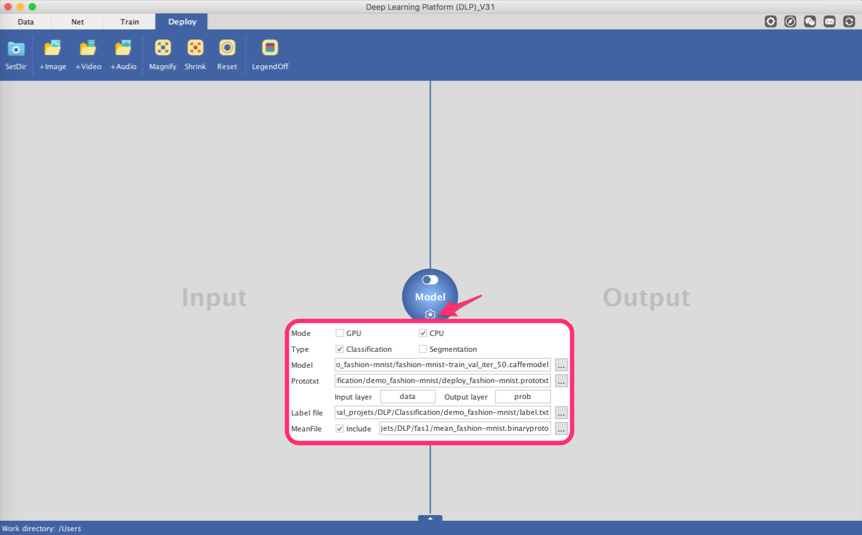
Once we have these two files ready and saved locally, we are now all set. But before we start making predictions on new data, we have to tell DLP where to find these files (label.txt and deploy_fashion-mnist.prototxt), our trained Caffe model, and the mean file generated in step 3. And if you running a CPU-ONLY Caffe, you want to make sure that the Mode option is set to CPU.
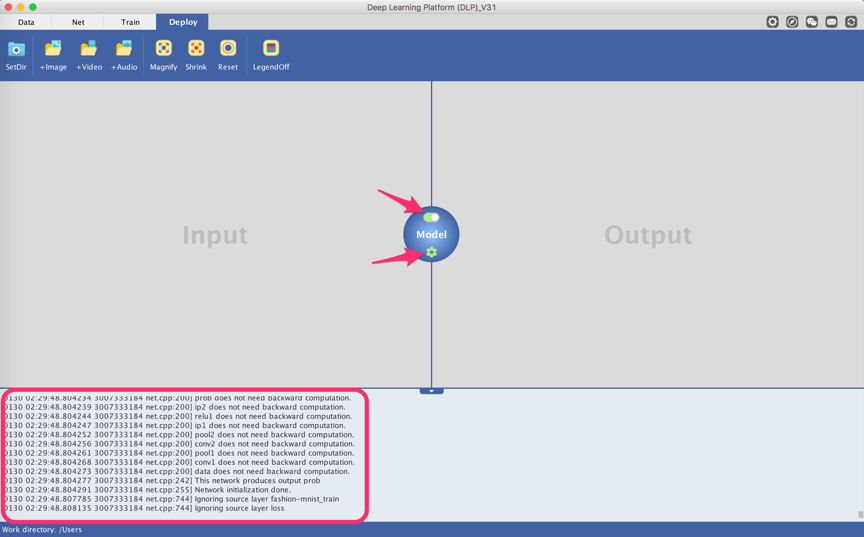
If all required parameters are set, the dropdown button will turn green. Next, turn on the toggle button by dragging it to the right. This will initialize DLP for prediction.
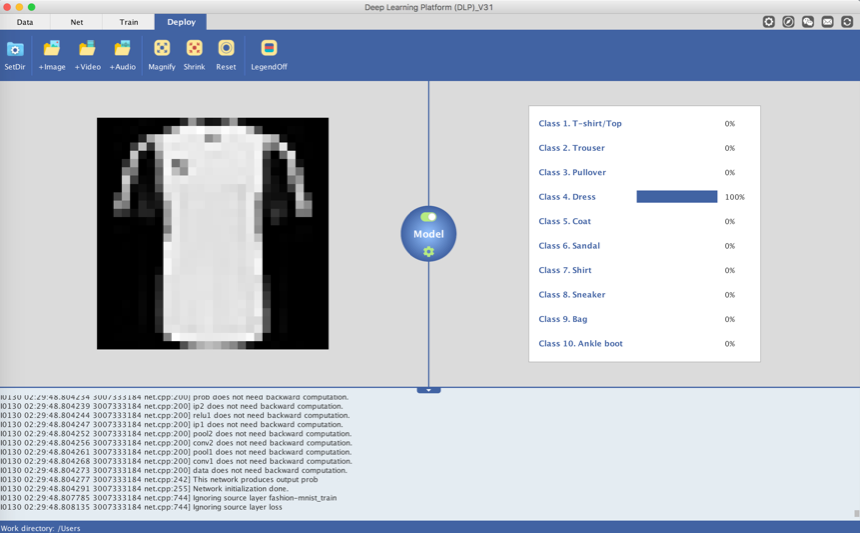
Then head to the Function Bar and click on the Image command to add an image input. The prediction to the input image will pop up at the right side of the Visualization Area.
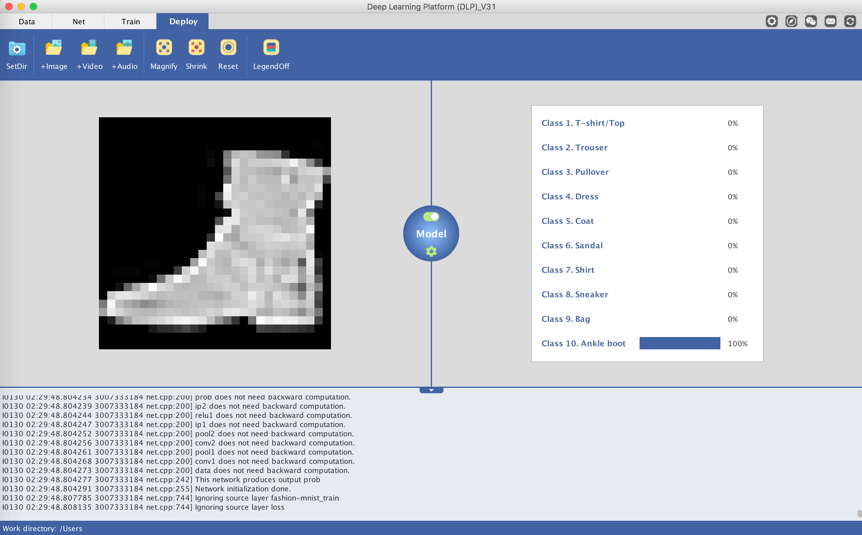
In my case, the classifier is 100% confident that the input image is a Dress. Let's try another input image from the test set of the fashion-mnist data.
Again, our classifier made the right prediction with a perfect confidence score.
Conclusion
In this tutorial, we walked through the process of training a convolution neural networks classifier using DLP. We covered DLP core modules namely, Data, Net, Train, and Deploy. From here, there are number of things you can try:
1. Train for longer: we trained our classifier for just 50 iterations. Training for a longer number of iterations will surely improve the accuracy of our classifier.
2. Try other net architectures: DLP net library contains some of the most popular (and effective) CNN architectures for classification. You can try them out.
3. Train on your own data: we used the fashion-mnist dataset to illustrate how to perform classification from data preparation to prediction on unseen data using DLP. The steps described above will be similar for any datasets for classification.